The world of nutrition is vast and ever-evolving. With a plethora of food products available in the market, making informed choices becomes a challenge. Recognizing this, the agency “Santé publique France” initiated a call for innovative application ideas related to nutrition. We heeded the call and embarked on a journey to develop a unique application that not only provides insights into various food products but also suggests healthier alternatives.
The Inspiration Behind the App
The “Santé publique France” agency, dedicated to public health in France, recognized the need for innovative solutions to address the challenges of modern nutrition. With the vast dataset from Open Food Facts at our disposal, we saw an opportunity to create an application that could make a difference.
Our Streamlit App: Features & Highlights
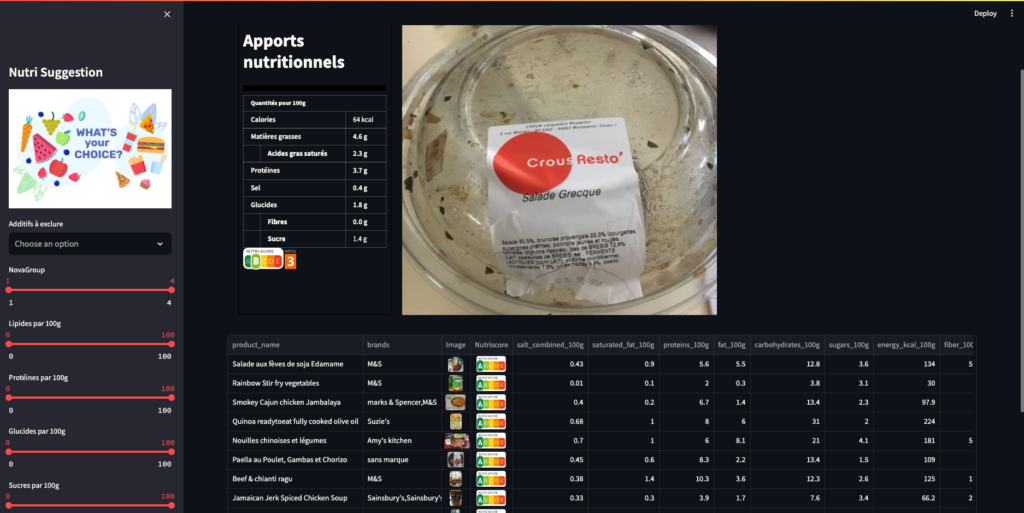
Our application is designed to be user-friendly and informative:
Product Insights: Users can select a product and view its comprehensive nutritional information.
Healthier Alternatives: The app suggests healthier alternatives based on user-defined criteria and the product’s nutritional score.
Visual Analytics: Throughout the app, users are presented with clear and concise visualizations, making the data easy to understand, even for those new to nutrition.
The Technical Journey
Data Processing: The Open Food Facts dataset was our primary resource. We meticulously cleaned and processed this data, ensuring its reliability. This involved handling missing values, identifying outliers, and automating these processes for future scalability.
Univariate & Multivariate Analysis: We conducted thorough analyses to understand individual variables and their interrelationships. This was crucial in developing the recommendation engine for healthier alternatives.
Application Ideation: Drawing inspiration from real-life scenarios, like David’s sports nutrition focus, Aurélia’s quest for healthier chips, and Sylvain’s comprehensive product rating system, we envisioned an app that catered to diverse user needs.
Deployment with Docker
To ensure our application’s consistent performance across different environments, we turned to Docker. Docker allowed us to containerize our app, ensuring its smooth and consistent operation irrespective of the deployment environment.
Conclusion & Future Prospects
Our Streamlit app is a testament to the power of data-driven solutions in addressing real-world challenges. By leveraging the Open Food Facts dataset and the simplicity of Streamlit, we’ve created an application that empowers users to make informed nutritional choices. As we look to the future, we’re excited about the potential enhancements and the broader impact our app can have on public health.
In the ever-evolving landscape of technology, Automatic Speech Recognition (ASR) stands out as a pivotal advancement, turning spoken language into written text. In this article, we delve into a Python script that seamlessly integrates OpenAI’s Whisper ASR with Streamlit, a popular web app framework for Python, to transcribe audio files and present the results in a user-friendly interface.
Script Overview:
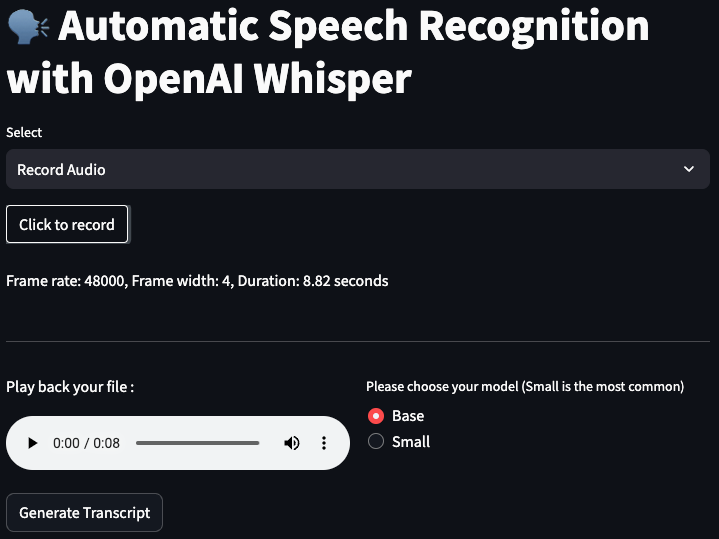
The script in focus utilizes several Python libraries, including os, pathlib, whisper, streamlit, and pydub, to create a web application capable of converting uploaded audio files into text transcripts. The application supports a variety of audio formats such as WAV, MP3, MP4, OGG, WMA, AAC, FLAC, and FLV.
Key Components:
Directory Setup: The script defines three main directories: UPLOAD_DIR for storing uploaded audio files, DOWNLOAD_DIR for saving converted MP3 files, and TRANSCRIPT_DIR for keeping the generated transcripts.
Audio Conversion: The convert_to_mp3 function is responsible for converting the uploaded audio file into MP3 format, regardless of its original format. This is achieved using a mapping of file extensions to corresponding conversion methods provided by the pydub library.
Transcription Process: The transcribe_audio function leverages OpenAI’s Whisper ASR model to transcribe the converted audio file. Users have the option to choose the model type (Tiny, Base, Small) for transcription.
Transcript Storage: The write_transcript function writes the generated transcript to a text file, stored in the TRANSCRIPT_DIR.
User Interface: Streamlit is employed to create an intuitive user interface, allowing users to upload audio files, choose the ASR model, generate transcripts, and download the results. The interface also provides playback functionality for the uploaded audio file.
Usage:
Uploading Audio File: Users can upload their audio file through the Streamlit interface, where they are prompted to choose the file and the ASR model type.
Generating Transcript: Upon clicking the “Generate Transcript” button, the script processes the audio file, transcribes it using the selected Whisper model, and displays a formatted transcript in a toggleable section.
Downloading Transcript: Users have the option to download the generated transcript as a text file directly from the application.
Conclusion:
This innovative script exemplifies the integration of Automatic Speech Recognition technology with web applications, offering a practical solution for transcribing audio files. By combining the capabilities of OpenAI’s Whisper and Streamlit, it provides a versatile tool that caters to a wide range of audio formats and user preferences. Whether for academic research, content creation, or accessibility, this application stands as a testament to the boundless possibilities of ASR technology in enhancing digital communication.
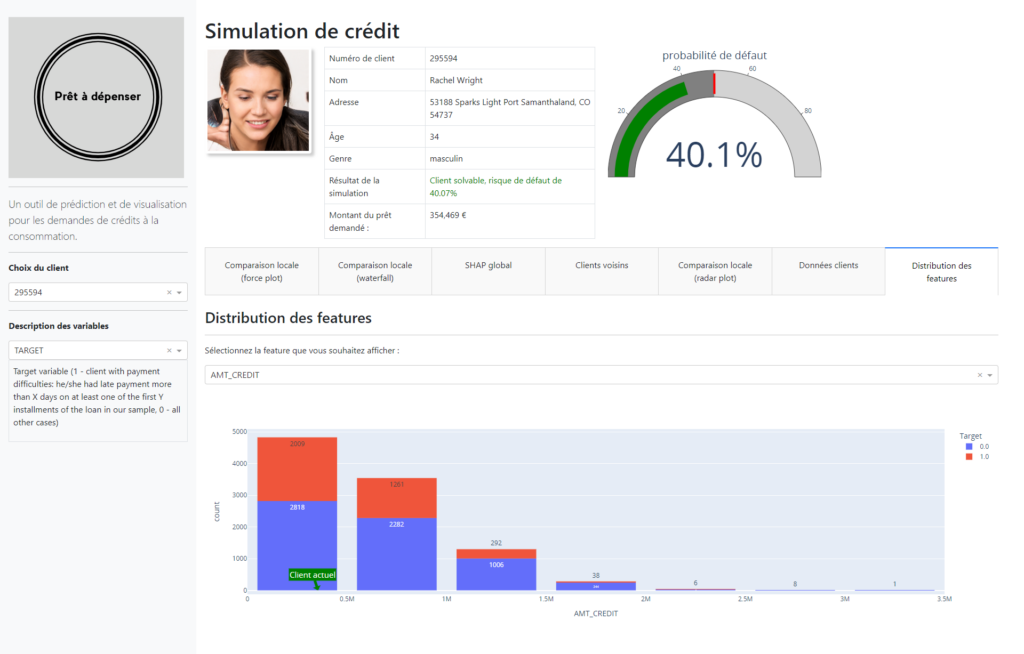
Background: In the face of the rapidly evolving financial market and the increasing demand for transparency from clients, Credit Match sought our expertise to develop an innovative credit scoring solution. The goal was twofold: to optimize the credit granting decision process and to enhance client relations through transparent communication.
Proposed Solution:
Automated Scoring Model: We crafted an advanced classification algorithm that leverages a myriad of data sources, including behavioral data and information from third-party financial entities. This algorithm is adept at accurately predicting the likelihood of a client repaying their credit.
Interactive Dashboard: Addressing the need for transparency, we designed an interactive dashboard tailored for client relationship managers. This dashboard not only elucidates credit granting decisions but also provides clients with easy access to their personal information.
Technologies Deployed:
Analysis and Modeling: We utilized Kaggle kernels to facilitate exploratory analysis, data preparation, and feature engineering. These kernels were adapted to meet the specific needs of Credit Match.
Dashboard: Based on the provided specifications, we chose [Dash/Bokeh/Streamlit] to develop the interactive dashboard.
MLOps: To ensure regular and efficient model updates, we implemented an MLOps approach, relying on Open Source tools.
Data Drift Detection: The evidently library was integrated to anticipate and detect any future data discrepancies, thus ensuring the model’s long-term robustness.
Deployment: The solution was deployed on [Azure webapp/PythonAnywhere/Heroku], ensuring optimal availability and performance.
Results: Our model demonstrated outstanding performance, with an AUC exceeding 0.82. However, we took precautions to avoid any overfitting. Moreover, considering Credit Match’s business specifics, we optimized the model to minimize costs associated with prediction errors.
Documentation: A detailed technical note was provided to Credit Match, allowing for transparent sharing of our approach, from model conception to Data Drift analysis.
This project is an analysis of data from education systems, aimed at providing insights into the trends and patterns of the education sector. The data is sourced from various educational institutions, and the project aims to extract meaningful information from this data to inform education policies and practices.
Getting Started
To get started with this project, you will need to have a basic understanding of data analysis and data visualization tools. The project is written in Python, and you will need to have Python 3.x installed on your system.
You can download the source code from the GitHub repository and install the necessary dependencies using pip. Once you have installed the dependencies, you can run the project using the command line.
Project Structure
The project is organized into several directories, each of which contains code related to a specific aspect of the project. The directories are as follows:
data: contains the data used in the project.
notebooks: contains Jupyter notebooks used for data analysis and visualization.
scripts: contains Python scripts used for data preprocessing and analysis.
reports: contains reports generated from the data analysis.
In the vast ocean of unstructured data, PDFs stand out as one of the most common and widely accepted formats for sharing information. From research papers to company reports, these files are ubiquitous. But with the ever-growing volume of information, navigating and extracting relevant insights from these documents can be daunting. Enter our recent project: a Streamlit application leveraging OpenAI to answer questions about the content of uploaded PDFs. In this article, we’ll dive into the technicalities and the exciting outcomes of this endeavor.
The Challenge
While PDFs are great for preserving the layout and formatting of documents, extracting and processing their content programmatically can be challenging. Our goal was simple but ambitious: develop an application where users can upload a PDF and then ask questions related to its content, receiving relevant answers in return.
The Stack
Streamlit: A fast, open-source tool that allows developers to create machine learning and data applications in a breeze.
OpenAI: Leveraging the power of NLP models for text embeddings and semantic understanding.
PyPDF2: A Python library to extract text from PDF files.
langchain (custom modules): For text splitting, embeddings, and more.
The Process
PDF Upload and Text Extraction: Once a user uploads a PDF, we use PyPDF2 to extract its text content, ensuring the preservation of the sequence of words.
Text Splitting: Given that PDFs can be extensive, we implemented the CharacterTextSplitter from langchain to break down the text into manageable chunks. This modular approach ensures efficiency and high-quality results in the subsequent steps.
Text Embedding: We employed OpenAIEmbeddings from langchain to convert these chunks of text into vector representations. These embeddings capture the semantic essence of the text, paving the way for accurate similarity searches.
Building the Knowledge Base: Using FAISS from langchain, we constructed a knowledge base from the embeddings of the chunks, ensuring a swift and efficient retrieval process.
User Q&A: With the knowledge base in place, users can pose questions about the uploaded PDF. By performing a similarity search within our knowledge base, we retrieve the most relevant chunks corresponding to the user’s query.
Answer Extraction: Leveraging OpenAI, we implemented a question-answering mechanism, providing users with precise answers to their questions based on the content of the PDF.
Outcomes and Reflections
The Streamlit application stands as a testament to the power of combining user-friendly interfaces with potent NLP capabilities. While our project showcases significant success in answering questions about the content of a wide range of PDFs, there are always challenges:
Quality of Text Extraction: Some PDFs, especially those with images, tables, or non-standard fonts, may not yield perfect text extraction results.
Handling Large Documents: For exceedingly long PDFs, further optimizations may be required to maintain real-time processing.
Future Directions
Incorporate OCR (Optical Character Recognition): To handle PDFs that contain images with embedded text.
Expand to Other File Types: Venturing beyond PDFs to support other formats like DOCX or PPT.
Advanced Models: Exploring more advanced models from OpenAI or even fine-tuning models for specific domain knowledge.
Test the tool!You just need to upload a PDF file and ask your questions.