Automatic Speech Recognition: A Streamlit and Whisper Integration
Introduction:
In the ever-evolving landscape of technology, Automatic Speech Recognition (ASR) stands out as a pivotal advancement, turning spoken language into written text. In this article, we delve into a Python script that seamlessly integrates OpenAI’s Whisper ASR with Streamlit, a popular web app framework for Python, to transcribe audio files and present the results in a user-friendly interface.
Script Overview:
The script in focus utilizes several Python libraries, including os, pathlib, whisper, streamlit, and pydub, to create a web application capable of converting uploaded audio files into text transcripts. The application supports a variety of audio formats such as WAV, MP3, MP4, OGG, WMA, AAC, FLAC, and FLV.
Key Components:
- Directory Setup: The script defines three main directories:
UPLOAD_DIRfor storing uploaded audio files,DOWNLOAD_DIRfor saving converted MP3 files, andTRANSCRIPT_DIRfor keeping the generated transcripts. - Audio Conversion: The
convert_to_mp3function is responsible for converting the uploaded audio file into MP3 format, regardless of its original format. This is achieved using a mapping of file extensions to corresponding conversion methods provided by thepydublibrary. - Transcription Process: The
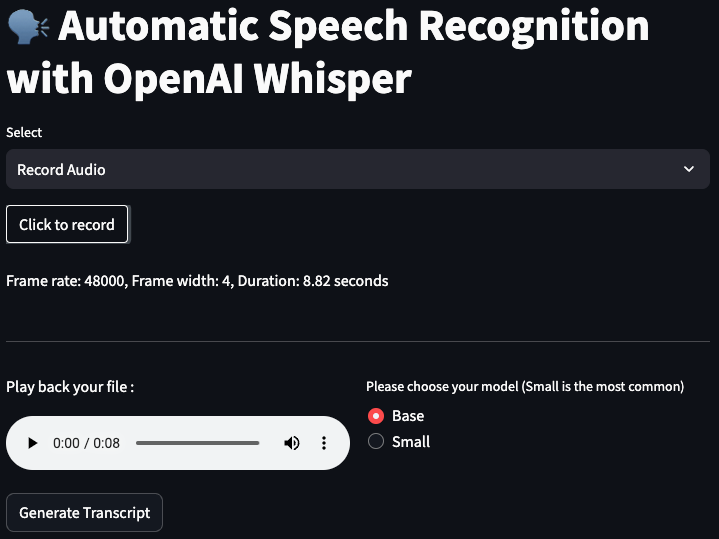
transcribe_audiofunction leverages OpenAI’s Whisper ASR model to transcribe the converted audio file. Users have the option to choose the model type (Tiny, Base, Small) for transcription. - Transcript Storage: The
write_transcriptfunction writes the generated transcript to a text file, stored in theTRANSCRIPT_DIR. - User Interface: Streamlit is employed to create an intuitive user interface, allowing users to upload audio files, choose the ASR model, generate transcripts, and download the results. The interface also provides playback functionality for the uploaded audio file.

Usage:
- Uploading Audio File: Users can upload their audio file through the Streamlit interface, where they are prompted to choose the file and the ASR model type.
- Generating Transcript: Upon clicking the “Generate Transcript” button, the script processes the audio file, transcribes it using the selected Whisper model, and displays a formatted transcript in a toggleable section.
- Downloading Transcript: Users have the option to download the generated transcript as a text file directly from the application.
Conclusion:
This innovative script exemplifies the integration of Automatic Speech Recognition technology with web applications, offering a practical solution for transcribing audio files. By combining the capabilities of OpenAI’s Whisper and Streamlit, it provides a versatile tool that caters to a wide range of audio formats and user preferences. Whether for academic research, content creation, or accessibility, this application stands as a testament to the boundless possibilities of ASR technology in enhancing digital communication.